Porto (Software Architectural Pattern)
![]()
Welcome to Porto
- Introduction
- Getting Started
- Components
- Typical Container Structure
- Porto Quality Attributes
- Implementations (Built with Porto)
- Feedback & Questions
Introduction
Porto is a modern software architectural pattern, consisting of guidelines, principles and patterns to help developers organize their code in a highly maintainable and reusable way.
Porto is a great option for medium to large sized web projects, as they tend to have higher complexity over time.
With Porto developers can build super scalable monolithics, which can be easily splitted into multiple micro-services whenever needed. While enabling the reusability of the business logic (Application Features), across multiple projects.
Porto inherits concepts from the DDD (Domain Driven Design), Modular, Micro Kernel, MVC (Model View Controller), Layered and ADR (Action Domain Responder) architectures.
And it adheres to a list of convenient design principles such as SOLID, OOP, LIFT, DRY, CoC, GRASP, Generalization, High Cohesion and Low Coupling.
It started as an experimental architecture, aiming at solving the common problems web developers face, when building large projects.
Feedbacks & Contributions are much appreciated.
“Simplicity is prerequisite for reliability.” — Edsger Dijkstra
Getting Started
Layers Overview
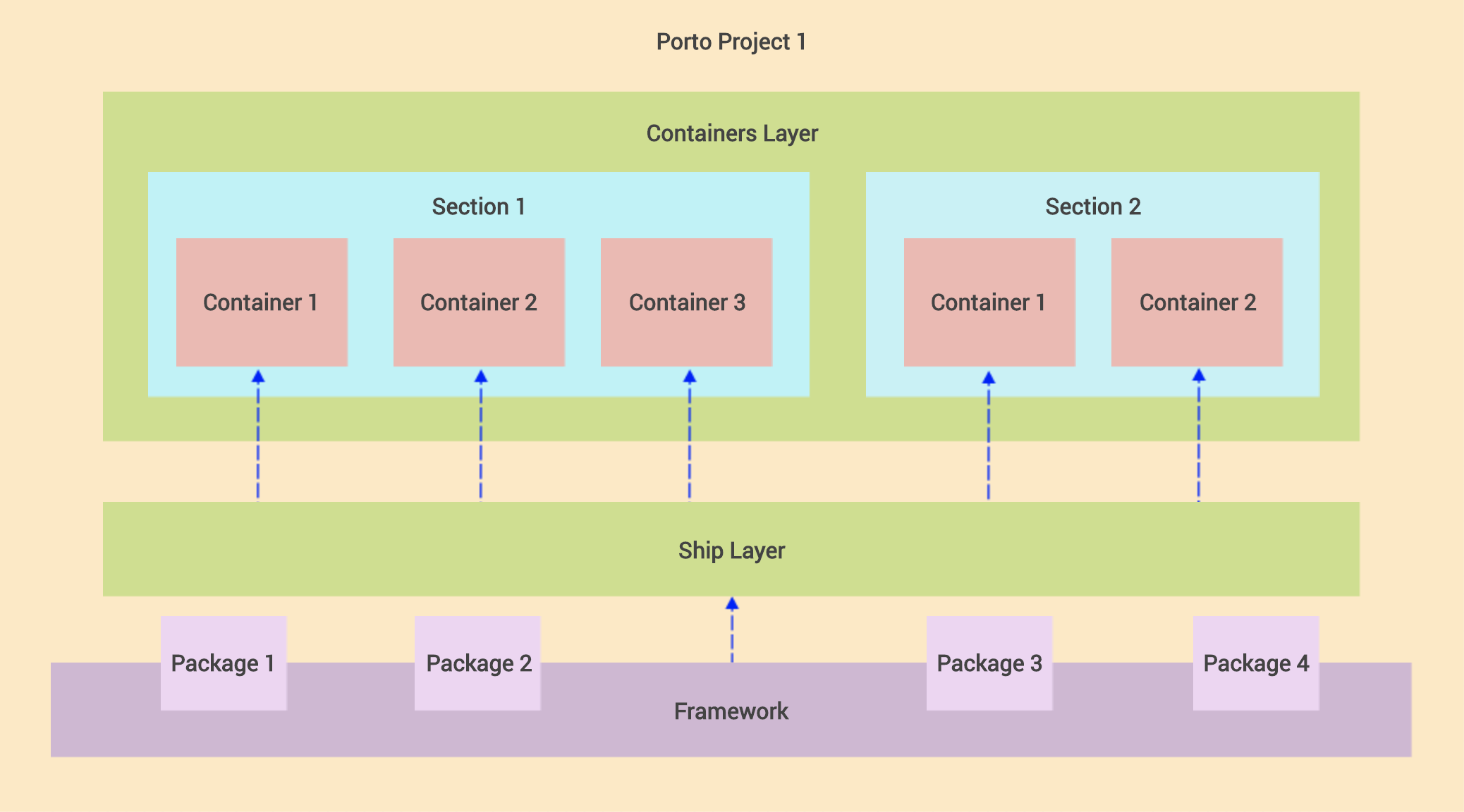
At its core Porto consists of 2 layers “folders” Containers & Ship.
- The Containers layer holds all your application business logic code.
- The Ship layer holds the infrastructure code (your shared code between all Containers).
These layers can be created anywhere inside any framework of choice.
(Example: in Laravel or Rails they can be created in the app/ directory or in a new src/ directory at the root.)
Visual Overview
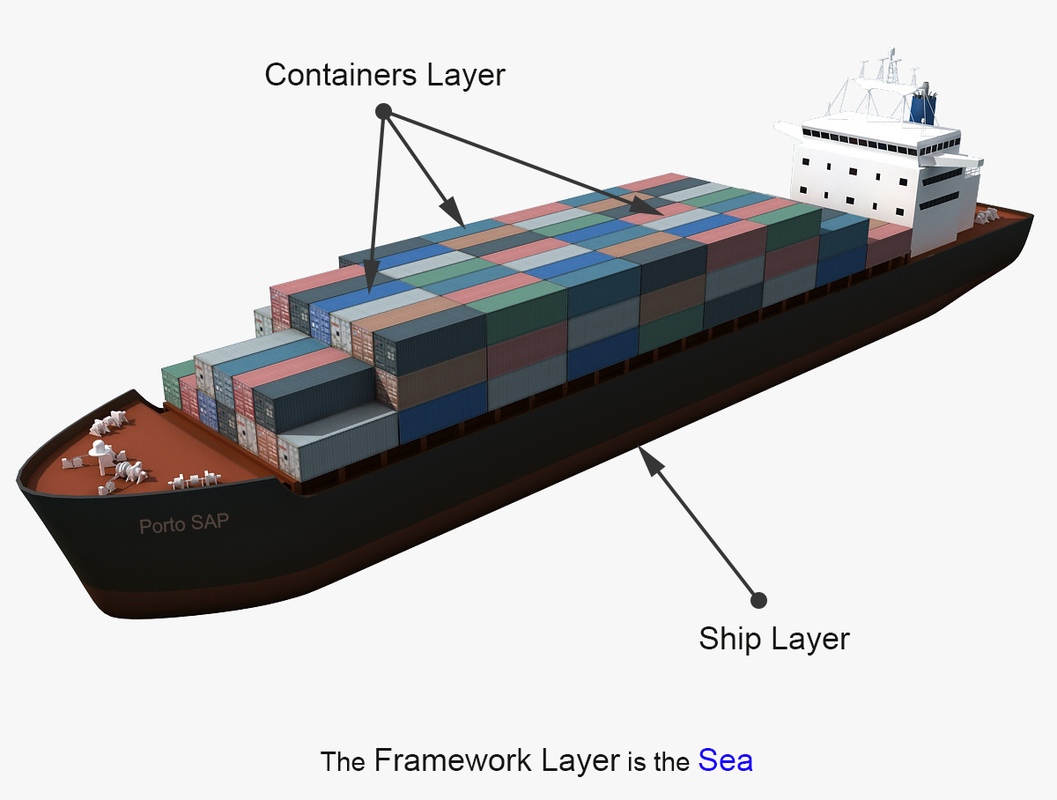
Before diving deeper, let’s understand the different levels of code we will have in your code base:
Code Levels
- Low-level code: the framework code (implements basic operations like reading files from a disk, or interacting with a database). Usually lives in the Vendor directory.
- Mid-level code: the application general code (implements functionality that serves the High-level code. And it relies on the Low-level code to function). Should be in the
Shiplayer. - High-level code: the business logic code (encapsulates complex logic and relies on the Mid-level code to function). Should be in the
Containerslayer.
Layers Diagram
The Containers layer (cargo containers) >> relies >> on the Ship layer (cargo ship) >> relies >> on the Framework (sea).
Monolithic to “Micro” Services
Porto is designed to scale with you! While most companies shift from Monolithic to Micro-Services (and most recently Serverless) as they scale up. Porto offers the flexibility to deflate your Monolithic into Micro-Services (or SOA) at any time with the least effort possible.
In Porto terms a Monolithic is equal to one cargo ship of Containers, while Micro Services is equal to multiple cargo ships of Containers. (Disregarding their sizes).
Porto offers the flexibility to start small with a single well organized Monolithic service and grow whenever you need, by extracting containers into multiple services as your team grows.
This is possible becuase Porto organizes your code into Containers, which are grouped into isolated Sections. A section can be later extracted out with all it’s related containers to be depolyed separatly as you scale.
As you can imagine operating two or more ships in the sea rather than a single one, will increase the cost of maintenance (two repositories, two CI pipelines,…) but also gives you flexibility, where each ship can run at different speed and direction. This technially translates to each service scaling differently based on the traffic it expect.
How Sections “Services” communicate together is completely up to the developers, even though Porto recomands using Events and/or Commands.
1) Ship Layer
The Ship layer, contains the Parent “Base” classes (classes extended by every single component) and some Utility Code.
The Parent classes “Base classes” of the Ship layer gives full control over the Container’s Components (for example adding a function to the Base Model class, makes it available in every Model in your Containers).
The Ship layer, also plays an important role in separating the Application code from the Framework code. Which facilitates upgrading the Framework without affecting the Application code.
In Porto the Ship layer is very slim, it does NOT contain common reusable functionalities such as Authentication or Authorization, since all these functionalities are provided by Containers, to be replaced whenever needed. Giving the developers more flexibility.
Ship Structure
The Ship layer, contains the following types of codes:
- The Core Code: is the engine of the ship, that auto-register and auto-load all your Container’s Components to boot your Application. It contains most of the magical code that handles everything that is not part of your business logic. And mostly contains code that facilitate the development by extending the framework features.
- The Containers shared code
- Parents Classes: the base classes of each Component in your Container. (Adding functions to the parent classes makes them available in every Container). Parents are made to contain shared code between your Containers.
- Generic Classes: the reusable features and classes which can be used by every Container. Such as, Global Exceptions, Application Middleware’s, Global Config files, etc.
Note: All the Container’s Components MUST extend or inherit from the Ship layer (in particular the Parent’s folder).
When separating the Core to an external package, the Ship Parents should extend from the Core Parents (can be named Abstract, since most of the them supposed to be Abstract Classes). The Ship Parents holds your custom Application shared business logic, while the Core Parents (Abstracts) holds your framework common code, basically anything that is not business logic should be hidden from the actual Application being developed.
2) Containers Layer
Porto manages the complexity of a problem by breaking it down to smaller manageable Containers.
The Containers layer is where the Application specific business logic lives (Application features/functionalities). You will spend 90% of your time at this layer.
Containers
A Container can be a feature, or can be a wrapper around a RESTful API resource, or anything else.
Example 1:
“In a TODO App, the ‘Task’, ‘User’ and ‘Calendar’ objects each would live in a different Container, were each has its own Routes, Controllers, Models, Exceptions, etc. And each Container is responsible for receiving requests and returning responses from whichever supported UI (Web, API..).”
It’s advised to use a Single Model per Container, however in some cases you may need more than a single Model and that’s totally fine. (Even if you have a single Model you could also have Values “AKA Value Objects” (Values are similar to Models but that do not get represented in the DB on their own tables but as data on the Models) these objects get built automatically after their data is fetched from the DB such as Price, Location, Time…)
Just keep in mind two Models means two Repositories, two Transformers, etc. Unless you want to use both Models always together, do split them into 2 Containers.
Note: if you have high dependecies between two containers by nature, than placing them in the same Section would make reusing them easier in other projects.
Example 2:
If you look at Apiato (the first project implementing Porto), you will notice that Authentication and Authorization are both features provided as Containers.
Basic Containers Structure
Container 1
├── Actions
├── Tasks
├── Models
└── UI
├── WEB
│ ├── Routes
│ ├── Controllers
│ └── Views
├── API
│ ├── Routes
│ ├── Controllers
│ └── Transformers
└── CLI
├── Routes
└── Commands
Container 2
├── Actions
├── Tasks
├── Models
└── UI
├── WEB
│ ├── Routes
│ ├── Controllers
│ └── Views
├── API
│ ├── Routes
│ ├── Controllers
│ └── Transformers
└── CLI
├── Routes
└── Commands
Containers Communication
- A Container MAY depends on one or many other Containers. (Wihin the same Section.)
- A Controller MAY call Tasks from another Container.
- A Model MAY have a relationship with a Model from another Containers.
- Other forms of communications are also possible, such as via Events and Commands.
If you use Event based communcations between containers, you could use the same mechanism after spliting your code base into multi services.
Note: If you’re not familiar with separating your code into Modules/Domains, or for some reason you don’t prefer that approach. You can create your entire Application in a single Container. (Not recommended but absolutely possible).
Sections
Section are another very important aspect in the Porto architecture.
A Section is a group of related containers. It can be a service (micro or bigger), or a sub-system within the main system, or antyhing else.
Think of a Section as a rows of containers on a cargo ship. Well organized containers in rows, speeds up the loading and unloading of related containers for a specific customer.
The basic definition of a Section is a folder that contains related Containers. However the benifits are huge. (A section is equivalent to a bounded context from the Domain-driven design) Each section represents a portion of your system and is completely isolated from other sections.
A Section can be deployed separatly.
Example 1:
If you’re building a racing game like Need for Speed, you may have the following two sections: the Race Section and the Lobby Section, where each section contains a Car Container and a Car Model inside it, but with different properties and functions. In this example the Car Model of the Race section can contain the business logic for accelerating and controlling the car, while the Car Model of the Lobby Section contains the business logic for customizing the car (color, accessories..) before the race.
Sections allows separating large Model into smaller ones. And they can provide boundaries for different Models in your system.
If you prefer simplicity or you have only single team working on the project, you can have no Sections at all (where all Containers live in the containers folder) which means your project is a single section. In this case if the project grew quickly and you decided you need to start using sections, you can make a new project also with a single section, this is known as Micro-Services. In Micro-Services each section “project portion” live in its own project (repository) and they can communicate over the network usually using the HTTP protocol.
Example 2:
In a typical e-commerce application you can have the following sections: Inventory Section, Shipping Section, Order Section, Payment Section, Catalog Section and more…
As you can imagine each of these Sections can be a micro-service by itself. And can be extracted and deployed on its own server based on the traffic it receives.
Sections Communication
- A Section MUST be isolated and SHOULD NOT depends on any other Section.
- A Section MAY listen to Events fired by other Sections. (Commands can be used as alternative to Events).
Components
In the Container layer there’s a set of Components “Classes” with predefined responsibilities.
Every single piece of code you write should live in a Component (class function). Porto defines a huge list of those Components for you, with a set guidelines to follow when using them, to keep the development process smooth.
Components ensures consistency and make your code easier to maintain as you already know where each piece of code should be found.
Components Types
Every Container consists of a number of Components, in Porto the Components are split into two Types:
Main Components and Optional Components.
1) Main Components
You must use these Components as they are essential for almost all types of Web Apps:
Routes - Controllers - Requests - Actions - Tasks - Models - Views - Transformers.
Views: should be used in case the App serves HTML pages.
Transformers: should be used in case the App serves JSON or XML data.
1.1) Main Components Interaction Diagram
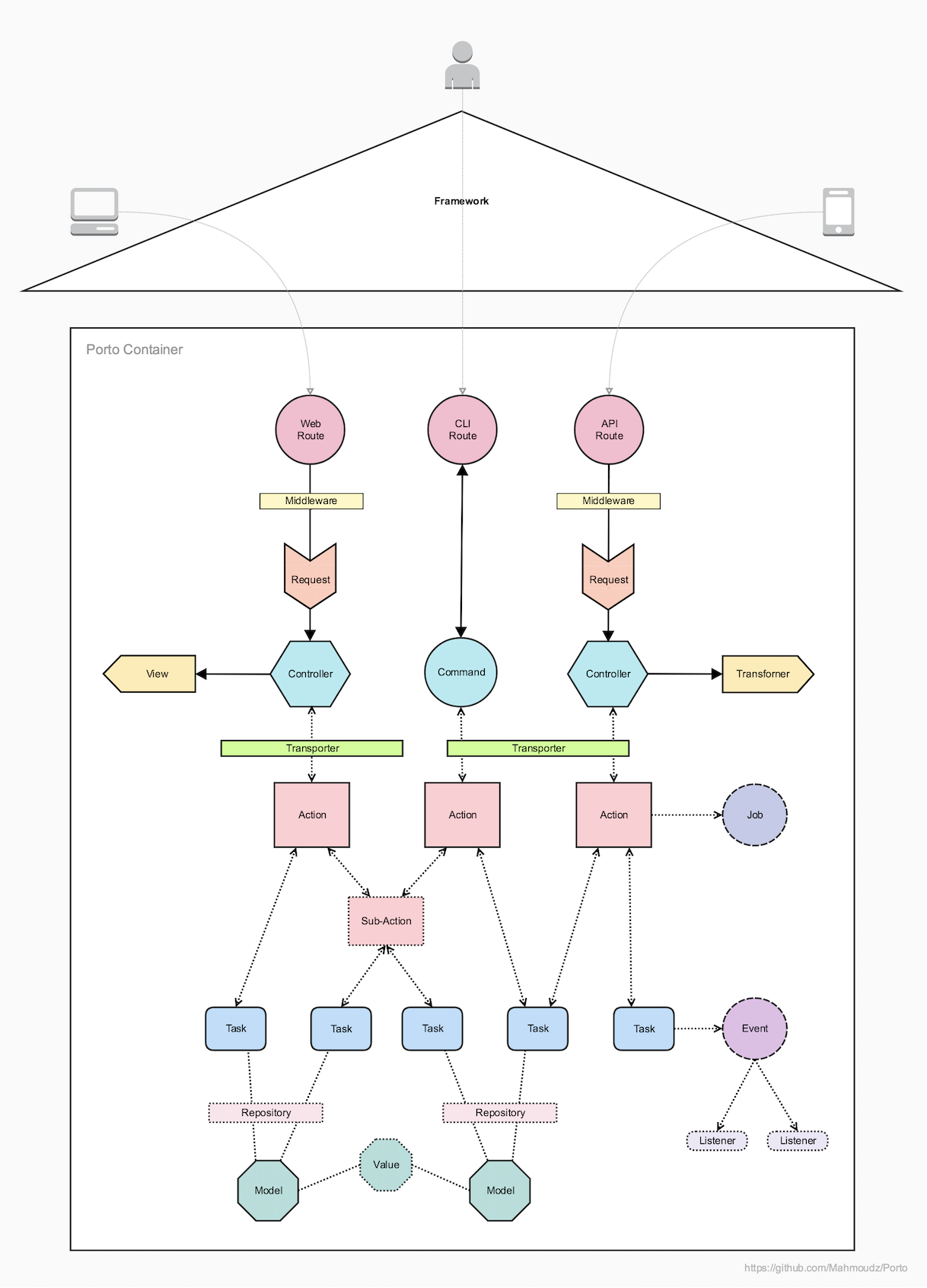
1.2) The Request Life Cycle
A basic API call scenario, navigating through the main components:
- User calls an
Endpointin aRoutefile. Endpointcalls aMiddlewareto handle the Authentication.Endpointcalls itsControllerfunction.Requestinjected in theControllerautomatically applies the request validation & authorization rules.Controllercalls anActionand pass eachRequestdata to it.Actiondo the business logic, OR can call as manyTasksas needed to do the reusable subsets of the business logic.Tasksdo a reusable subsets of the business logic (ATaskcan do a single portion of the main Action).Actionprepares data to be returned to theController, some data can be collected from theTasks.Controllerbuilds the response using aView(orTransformer) and send it back to the User.
1.3) Main Components Definitions & Principles
Click on the arrows below to read about each component.
Routes
Routes are the first receivers of the HTTP requests.
The Routes are responsible for mapping all the incoming HTTP requests to their controller’s functions.
The Routes files contain Endpoints (URL patterns that identify the incoming request).
When an HTTP request hits your Application, the Endpoints match with the URL pattern and make the call to the corresponding Controller function.
Principles:
- There are three types of Routes, API Routes, Web Routes and CLI Routes.
- The API Routes files SHOULD be separated from the Web Routes files, each in its own folder.
- The Web Routes folder will contain only the Web Endpoints, (accessible by Web browsers); And the API Routes folder will contain only the API Endpoints, (accessible by any consumer App).
- Every Container SHOULD have its own Routes.
- Every Route file SHOULD contain a single Endpoint.
- The Endpoint job is to call a function on the corresponding Controller once a request of any type is made. (It SHOULD NOT do anything else).
Controllers
Controllers are responsible for validating the request, serving the request data and building a response. Validation and response, happens in separate classes, but triggered from the Controller.
The Controllers concept is the same as in MVC (They are the C in MVC), but with limited and predefined responsibilities.
Principles:
- Controllers SHOULD NOT know anything about the business logic or about any business object.
- A Controller SHOULD only do the following jobs:
- Reading a Request data (user input)
- Calling an Action (and passing request data to it)
- Building a Response (usually build response based on the data collected from the Action call)
- Controllers SHOULD NOT have any form of business logic. (It SHOULD call an Action to perform the business logic).
- Controllers SHOULD NOT call Container Tasks. They MAY only call Actions. (And then Actions can call Container Tasks).
- Controllers CAN be called by Routes Endpoints only.
- Every Container UI folder (Web, API, CLI) will have its own Controllers.
You may wonder why we need the Controller! when we can directly call the Action from the Route. The Controller layer helps making the Action reusable in multiple UI’s (Web & API), since it doesn’t build a response, and that reduces the amount of code duplication across different UI’s.
Here’s an example below:
- UI (Web): Route
W-R1-> ControllerW-C1-> ActionA1. - UI (API): Route
A-R1-> ControllerA-C1-> ActionA1.
As you can see in the example above the Action A1 was used by both routes W-R1 and A-R1, with the help of the Controllers layer that lives in each UI.
Requests
Requests mainly serve the user input in the application. And they are very useful to automatically apply the Validation and Authorization rules.
Requests are the best place to apply validations, since the validations rules will be related to every request. Requests can also check the Authorization, e.g. check if this user has access to this controller function. (Example: check if a specific user owns a product before deleting it, or check if this user is an admin to edit something).
Principles:
- A Request MAY hold the Validation / Authorization rules.
- Requests SHOULD only be injected in Controllers. Once injected they automatically check if the request data matches the validation rules, and if the request input is not valid an Exception will be thrown.
- Requests MAY also be used for authorization, they can check if the user is authorized to make a request.
Actions
Actions represent the Use Cases of the Application (the actions that can be taken by a User or a Software in the Application).
Actions CAN hold business logic or/and they orchestrate the Tasks to perform the business logic.
Actions take data structures as inputs, manipulates them according to the business rules internally or through some Tasks, then output a new data structures.
Actions SHOULD NOT care how the Data is gathered, or how it will be represented.
By just looking at the Actions folder of a Container, you can determine what Use Cases (features) your Container provides. And by looking at all the Actions you can tell what an Application can do.
Principles:
- Every Action SHOULD be responsible for doing a single Use Case in the Application.
- An Action MAY retrieves data from Tasks and pass data to another Task.
- An Action MAY call multiple Tasks. (They can even call Tasks from other Containers as well!).
- Actions MAY return data to the Controller.
- Actions SHOULD NOT return a response. (The Controller’s job is to return a response).
- An Action SHOULD NOT call another Action (If you need to reuse a big chunk of business logic in multiple Actions, and this chunk is calling some Tasks, you can create a SubAction). See the SubAction section below.
- Actions are mainly used from Controllers. However, they can be used from Events Listeners, Commands and/or other Classes. But they SHOULD NOT be used from Tasks.
- Every Action SHOULD have only a single function named
run(). - The Action main function
run()can accept a Request Object in the parameter. - Actions are responsible of handling all expected Exceptions.
Tasks
The Tasks are the classes that hold the shared business logic between multiple Actions accross different Containers.
Every Task is responsible for a small part of the logic.
Tasks are optional, but in most cases you find yourself in need for them.
Example: if you have Action 1 that needs to find a record by its ID from the DB, then fires an Event. And you have an Action 2 that needs to find the same record by its ID, then makes a call to an external API. Since both actions are performing the “find a record by ID” logic, we can take that business logic and put it in it’s own class, that class is the Task. This Task is now reusable by both Actions and any other Action you might create in the future.
The rule is, whenever you see the possibility of reusing a piece of code from an Action, you should put that piece of code in a Task. Do not blindly create Tasks for everything, you can always start with writing all the business logic in an Action and only when you need to reuse it, create an a dedicated Task for it. (Refactoring is essential to adapt to the code growth).
Principles:
- Every Task SHOULD have a single responsibility (job).
- A Task MAY receive and return Data. (Task SHOULD NOT return a response, the Controller’s job is to return a response).
- A Task SHOULD NOT call another Task. Because that will takes us back to the Services Architecture and it’s a big mess.
- A Task SHOULD NOT call an Action. Because your code wouldn’t make any logical sense then!
- Tasks SHOULD only be called from Actions. (They could be called from Actions of other Containers as well!).
- Tasks usually have a single function
run(). However, they can have more functions with explicit names if needed. Making the Task class replace the ugly concept of function flags. Example: theFindUserTaskcan have 2 functionsbyIdandbyEmail, all internal functions MUST call therunfunction. In this example theruncan be called at the end of both funtions, after appending Criteria to the repository. - A Task SHOULD NOT be called from Controller. Because this leads to non-documented features in your code. It’s totally fine to have a lot of Actions “example:
FindUserByIdActionandFindUserByEmailActionwhere both Actions are calling the same Task” as well as it’s totally fine to have single ActionFindUserActionmaking a decision to which Task it should call. - A Task SHOULD NOT accept a Request object in any of its functions. It can take anything in its funtions parameters but never a Request object. This will keep free to use from anwyhere, and can be tested independently.
Models
The Models provide an abstraction for the data, they represent the data in the database. (They are the M in MVC).
Models are responsible for how the data should be handled. They make sure that data arrives properly into the backend store (e.g. Database).
Principles:
- A Model SHOULD NOT hold business logic, it can only hold the code and data that represents itself. (it’s relationships with other models, hidden fields, table name, fillable attributes,…)
- A single Container MAY contain multiple Models.
- A Model MAY define the Relations between itself and any other Models (in case a relation exist).
Views
Views contain the HTML served by your application.
Their main goal is to separate the application logic from the presentation logic. (They are the V in MVC).
Principles:
- Views can only be used from the Web Controllers.
- Views SHOULD be separated into multiple files and folders based on what they display.
- A single Container MAY contain multiple Views files.
Transformers
Transformers (are the short name for Responses Transformers).
They are equivalent to Views but for JSON Responses. While Views takes data and represent it in HTML, Transformers takes data and represent it in JSON.
Transformers are classes responsible for transforming Models into Arrays.
Transformers takes a Model or a group of Models “Collection” and converts it to a formatted serializable Array.
Principles:
- All API responses MUST be formatted via Transformers.
- Every Model (that gets returned by an API call) SHOULD have a Transformer.
- A single Container MAY have multiple Transformers.
- Usually every Model would have a Transformer.
Exceptions
Exceptions are also a form of output that should be expected (like an API exception) and well defined.
Principles:
- There are container Exceptions (live in Containers) and general Exceptions (live in Ship).
- Tasks, Sub-Tasks, Models and any class in general can throw a very specific Exception.
- The caller MUST handle all expected Exceptions from the called class.
- Actions MUST handle all Exceptions, and making sure they don’t leak to upper Components, and cause unexpected behaviors.
- Exceptions names SHOULD be as specific as possible and they SHOULD have a clear descriptive messages.
Sub-Actions
SubActions are designed to eliminate code duplication in Actions. Don’t get confused! SubActions do not replace Tasks.
While Tasks allows Actions to share a piece of functionality. SubActions allows Actions to share a sequence of Tasks.
The SubActions are created to solve a problem. The problem is: Sometimes you need to reuse a big chunk of business logic in multiple Actions. That chunk of code is already calling some Tasks. (Remember a Task SHOULD NOT call other Tasks) so how shall you reuse that chunk of code without creating a Task! The solution is create a SubAction.
Detailed Example: assuming an Action A1 is calling Task1, Task2 and Task3. And another Action A2 is calling Task2, Task3, Task4 and Task5. Notice both Actions are calling Tasks 2 and 3. To eliminate code duplication we can create a SubAction that contains all the common code between both Actions.
Principles:
- Sub-Actions MUST call Tasks. If a Sub-Actions is doing all the business logic, without the help of at least 1 Tasks, it probably shouldn’t be a Sub-Action but a Task instead.
- A Sub-Action MAY retrieves data from Tasks and pass data to another Task.
- A Sub-Action MAY call multiple Tasks. (They can even call Tasks from other Containers as well!).
- Sub-Actions MAY return data to the Action.
- Sub-Action SHOULD NOT return a response. (the Controller job is to return a response).
- Sub-Action SHOULD NOT call another Sub-Action. (try to avoid that as much as possible).
- Sub-Action SHOULD be used from Actions. However, they can be used from Events, Commands and/or other Classes. But they SHOULD NOT be used from Controllers or Tasks.
- Every Sub-Action SHOULD have only a single function named
run().
2) Optional Components
You can add these Components when you need them, based on your App needs, however some of them are highly recommended:
Tests - Events - Listeners - Commands - Migrations - Seeders - Factories - Middlewares - Repositories - Criteria - Policies - Service Providers - Contracts - Traits - Jobs - Values - Transporters - Mails - Notifications…
Typical Container Structure
A Container with a list of Main and Optional Components.
Container
├── Actions
├── Tasks
├── Models
├── Values
├── Events
├── Listeners
├── Policies
├── Exceptions
├── Contracts
├── Traits
├── Jobs
├── Notifications
├── Providers
├── Configs
├── Mails
│ ├── Templates
├── Data
│ ├── Migrations
│ ├── Seeders
│ ├── Factories
│ ├── Criteria
│ ├── Repositories
│ ├── Validators
│ ├── Transporters
│ └── Rules
├── Tests
│ ├── Unit
│ └── Traits
└── UI
├── API
│ ├── Routes
│ ├── Controllers
│ ├── Requests
│ ├── Transformers
│ └── Tests
│ └── Functional
├── WEB
│ ├── Routes
│ ├── Controllers
│ ├── Requests
│ ├── Views
│ └── Tests
│ └── Acceptance
└── CLI
├── Routes
├── Commands
└── Tests
└── Functional
Porto Quality Attributes
The benefits of using Porto.
Modularity & Reusability
In Porto, your application business logic lives in Containers. Porto Containers are similar in nature to the Modules (from the Modular architecture) and Domains (from the DDD architecture).
Containers can depend on other Containers, similar to how a layer can depend on other layers in a layered architecture.
Porto’s rules and guidelines minimizes and defines the dependecies directions between Containers, to avoid circular references between them.
And it allows the grouping of related Containers into sections, in order to reuse them together in different projects. (each Section contains a reusable portion of your application business logic).
In terms of dependency management, the developer is free to move each Container to its own repository or keep all Containers together under single repository.
Maintainability & Scalability
Porto aim to reduce maintance cost by saving developers time. It’s structured in a way to insure code decoupling, and forces consistency which all contribute to its maintainability.
Having a single function per class to describe a functionality, makes adding and removing features an easy process.
Porto has a very organized code base and a zero code decoupling. In addition to clear development workflow with predefined data flow and dependencies directions. That all contributes to its scalability.
Testability & Debuggability
Extremely adhering to the single responsibility principle by having single function per class, results in having super slim classes, which leads to easier testability.
In Porto each component expect the same type of input and output, which makes testing, mocking and stabbing very simple.
The Porto structure itself makes writing automated tests a smooth process. As it has a tests folder at the root of each Container for contaning the unit tests of your Tasks.
And a tests folder in each UI folder for contaning the functional tests (for testing each UI’s separately).
The secret of making the testing and debugging easy, is not only in the organization of the tests and pre defined responsiblity of the components but also in the decoupling of your code.
Adaptability & Evolvability
With Porto you can easily accommodate future changes with the least amount of efforts.
Let’s assume you have a web app that serves HTML and recently you decided that you need to have a Mobile app, hence you need an API.
Porto has pluggable UI’s (WEB, API & CLI) and this allows writting the business logic of your application first, then implementing a UI to interact with your code.
This gives the flexibility to adding interfaces whenever needed and adapting to future changes, with the least effort possible.
it is all possible because the Actions are the central organizing principle “not the controller” which are shared across multiple UI’s. And the UI’s are separated from the application business logic and separated from each others within each Container.
Usability & Learnability
Porto makes it super easy to locate any feature/functionality. And to understand what’s happening inside it.
That due to the usage of the domain expert language when naming the classes “components”. As well as the single function per class golden rule. Which allows you to find any Use Case (Action) in your code by just browsing the files.
Porto promises that you can find any feature implementation in less than 3 seconds! (example: if you are looking for where the user address is being validated - just go to the Address Container, open the list of Actions and search for ValidateUserAddressAction).
Extensibility & Flexibility
Porto’s takes future growth into consideration and it ensures your code remains maintainable no matter what the project size becomes.
It achieves this by its modular structure, separation of concerns and the organized coupling between the internal classes “Components”.
This allows modifications to be made without undesirable side effects.
Agility & Upgradability
Porto gives the ability to move quickly and easily.
It’s easy to make framework upgrades due to the complete separation between the App and the framework code through the Ship layer.
Implementations
Feel free to list your implementation here.
List of projects implementing the Porto architecture.
- PHP
- Laravel
- Apiato (By the Porto creator) A PHP Framework for building scalable API’s on top of Laravel.
- Laravel Large Project An example project to show how to build large projects with Porto.
- Zend Expressive
- Expressive Porto An implementation of the Porto architecture with Zend Expressive.
- Laravel
- JavaScript
- Python
- Django
- PyPorto A design for building scalable and testable applications with Django Rest Framework.
- Django
- Ruby
- Java
- C#
- …
Get in Touch
Your feedback is important.
For feedbacks, questions, or suggestions? We are on Slack.
![]()
Author
 Mahmoud Zalt Twitter: @mahmoudz Site: zalt.me |
Donations
Become a Github Sponsor.
Direct donation via Paypal.
Become a Patreon.
License
MIT © Mahmoud Zalt